
Guides
Cold calling scripts that actually work in 2026
The anatomy of a cold call that gets a yes, a full example script, how to handle the common objections, and how to log the call without breaking flow.
June 27, 2026 · 6 min read
What we build and how we think. Product updates, engineering deep-dives, and lessons from building an AI meeting notes platform.
The anatomy of a cold call that gets a yes, a full example script, how to handle the common objections, and how to log the call without breaking flow.

What conversation intelligence is, what it surfaces from calls, how it works, where it helps sales teams, and how it differs from plain AI meeting notes.

A practical guide to running a blameless post-mortem: the agenda, how to find the real root cause with the five whys, and how to turn lessons into fixes.

What meeting cadence means, the trade-offs between weekly, biweekly, and monthly, how to choose the right rhythm for your team, and how to audit it.

What to capture in meeting minutes, a simple template, and the fastest way to write them: record the meeting and let AI turn it into decisions and actions.

A practical guide to the EOS Level 10 Meeting: the 90-minute agenda, what each segment does, how IDS works, and the rules that keep it on track.
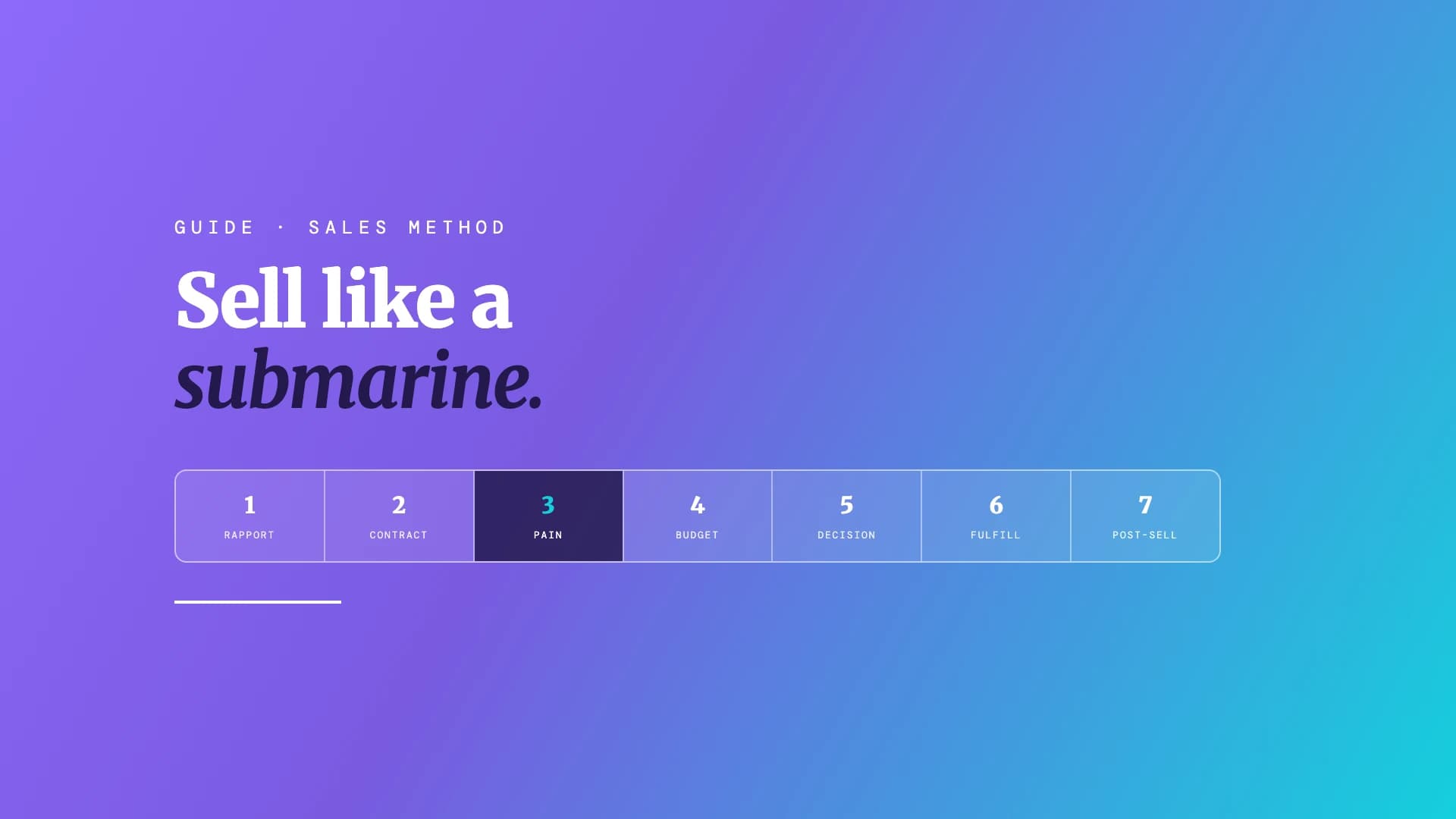
A clear guide to the Sandler Selling System: the submarine's 7 steps, the pain funnel, up-front contracts, and how it differs from traditional selling.

A practical staff meeting guide: an agenda that works, how to choose a cadence, the mistakes that waste everyone's time, and how to make items end in action.

What AI meeting notes and AI notetakers do, the bot vs bot-free question, how to get accurate results, the real limits, and the privacy rules to follow.

Three ways to transcribe audio to text, how to handle m4a, mp3, and meeting recordings, what accuracy to expect, and what to do with the transcript.

How to record a meeting on Google Meet, Microsoft Teams, and Zoom: the steps, where recordings save, how to record as a participant, and what to do next.
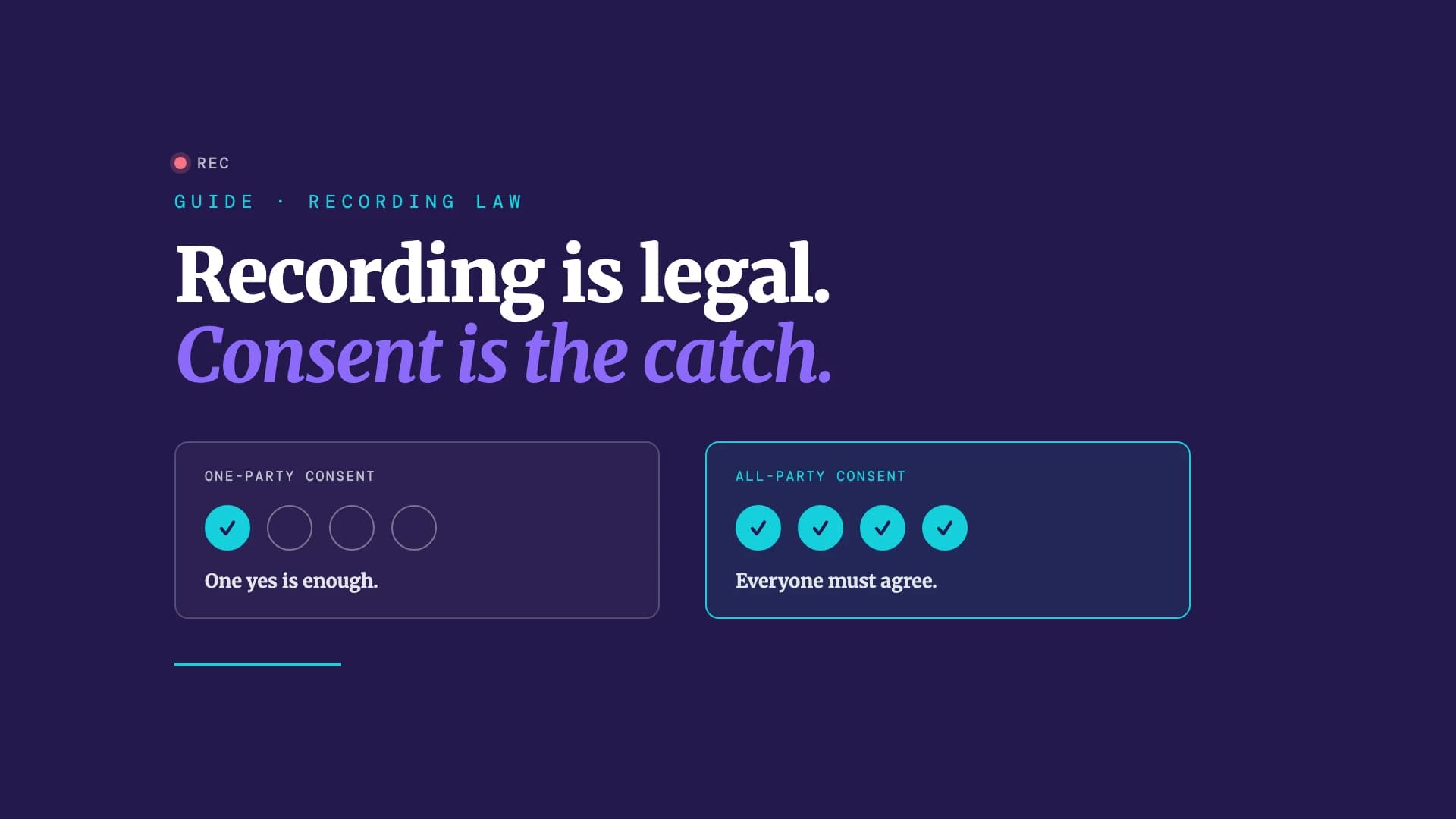
Recording a conversation you are part of is legal in most of the world, with a few strict exceptions. Here is how consent laws work across the US, EU, and Asia.

Push calls and meetings into Neural Summary from your own systems, and get summaries, action items, and Lens outputs back as signed webhooks. Works with Zapier, Make, and n8n, no code required.

We compared 8 AI note taking apps using real user reviews and hands-on testing, to find the best for meetings, sales, and privacy. Pricing and honest takes inside.

Why people remember diagrams better than text notes, how Mermaid lets you write diagrams as code, and how AI (and Neural Summary) draws them for you.

Why we built internationalization into the first commit, how we handle three layers of language (UI strings, AI-generated content, on-demand translation), and what we would do differently.

Why we invested a week in polish — preventing the dark mode white flash, replacing every spinner with layout-matched skeletons, and adding GPU-composited micro-animations. What each decision cost and what it changed.

The meeting AI space is crowded with tools competing on transcription quality. But the actual pain point is not 'I don't know what was said.' It is 'I still have to write the deliverable.' The market is optimizing the wrong phase.

How to take notes in Google Meet without losing the action. A practical 3-step guide: safeguard the audio, generate clean structured notes, and turn conversations into work artifacts. Works on every Google Meet plan, including free Gmail.

Why we moved transcription processing off the request cycle, added WebSocket with polling fallback, and how those decisions shaped our architecture.

How we built a cross-platform mobile app with Expo in five phases. Authentication sharing, upload queues, quota-aware retry logic, and the engineering behind graceful plan limits.

The five-category value ladder, the anatomy of a lens template, and how we evolved from generic summaries to consulting-grade output across 30 document types.

We audited our own codebase before launching V2 and found eight vulnerabilities, including a critical command injection. What we found, why each one existed, and the architectural patterns we adopted to prevent them.

Why we chose SSE over WebSocket for AI chat streaming, how citation buffering eliminated visual artifacts, and the architectural decisions behind multi-turn context and stop generation.

How we built cross-conversation AI chat with semantic search, streaming responses, and citations that reference specific timestamps and speakers across different conversations.

The old benchmark of eleven million meetings per day is more than a decade out of date. The modern number is closer to three hundred million. And almost none of them produce a finished deliverable.

Why we moved from markdown to structured JSON output, and the prompt patterns we developed over 30 templates to get consistent quality in five languages.

Why we built an audio splitting pipeline, what broke when real users started uploading browser recordings, and the fallback layers that made the system resilient.

From first commit to streaming AI chat, 671 commits later. The decisions that paid off, the ones I'd make differently, and what I learned building a full-stack AI product as a solo founder.

The real productivity bottleneck is not the meeting. It is the 90 minutes afterward, translating decisions into deliverables. Most meeting AI focuses on the wrong phase.

Most meeting tools stop at telling you what was said. The real value is generating the deliverable you would have written manually: the spec, the brief, the email, the backlog.

Independent consultants spend 25% of their week on post-meeting write-ups. That is where margins shrink. There is a faster way.

The thinking was done in minutes. The document took hours. That translation step is where momentum dies, and it does not have to be manual.