
A user uploads a 3-hour board meeting recording. The audio file is 800MB. Processing takes 8 minutes. During those 8 minutes, the user needs to know three things: that something is happening, how far along it is, and whether it succeeded or failed.
Without real-time progress, the user stares at a spinner for 8 minutes, wondering if the page froze. They refresh. The refresh disrupts the process. They upload again. Now there are two copies.
Real-time progress feedback for long-running AI tasks is not a nice-to-have. It is infrastructure.
Why we separated processing from the request cycle
Our first implementation processed transcriptions synchronously in the API handler. For short recordings, this worked. For a 90-minute board meeting, the HTTP connection would time out well before processing finished. Users saw a blank error page after waiting minutes.
We moved to a job queue backed by an in-memory store. When a user uploads a file, the API creates a job and returns immediately. The job enters the queue and waits for an available worker. Each worker picks up one job, processes it through the full pipeline (download, split, transcribe, summarize, generate analyses), and marks it complete.
This separation gave us three things we did not have before:
Retry and recovery. The queue detects stalled jobs that stop sending heartbeats and retries them automatically. Failed jobs retry with exponential backoff. A temporary API failure no longer permanently fails a transcription.
Predictable resource usage. Concurrency is configurable. We can scale workers independently from the API, matching processing capacity to available resources without affecting request handling.
A foundation for everything else. Progress tracking, multi-device sync, and zombie cleanup all depend on the queue being the single source of truth for job state. Without this separation, none of the following decisions would have been possible.
Choosing WebSocket for real-time delivery
With processing decoupled from the request, we needed a way to push progress updates back to the client. Polling the API every few seconds would work, but it would lag behind the actual state and add unnecessary load.
We chose WebSocket connections for real-time delivery. When the user opens the upload modal, the client establishes an authenticated WebSocket connection. The server tracks connections per user, not per session:
// When a user connects from a new device
handleConnection(socket) {
const userId = verifyToken(socket.token);
if (!this.userSockets.has(userId)) {
this.userSockets.set(userId, new Set());
}
this.userSockets.get(userId).add(socket.id);
}This was a deliberate architectural choice. Tracking per user means one user can have multiple active connections (multiple tabs, a laptop and a phone) and all of them receive the same progress events. We did not have to build separate logic for multi-device support. It came for free from the data model.
Progress stages
Jobs report progress at defined stages rather than arbitrary percentages:
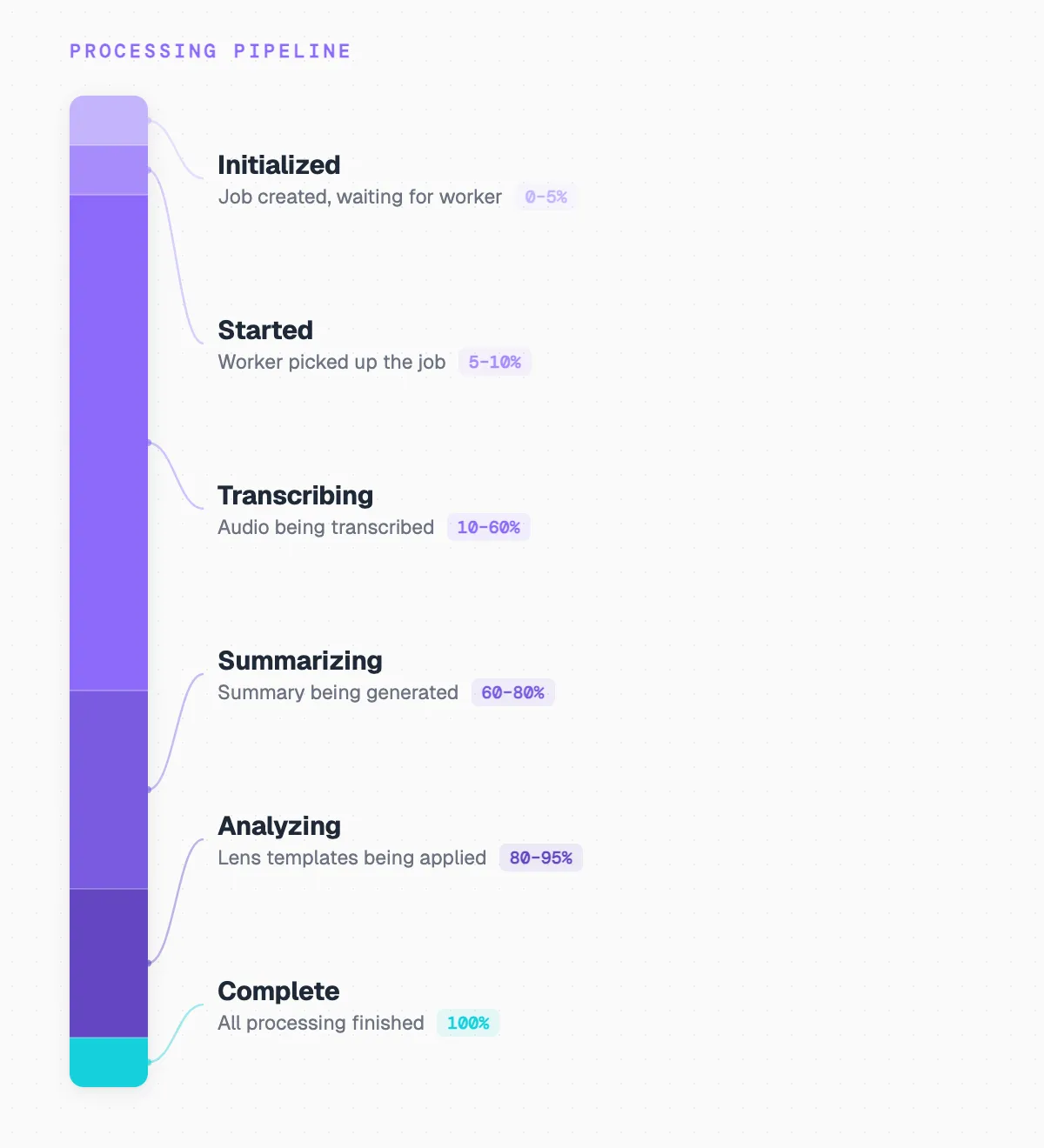
Transcription is the heavy lift, consuming roughly half the total processing time. We found that users respond better to "Summarizing your conversation..." than to "67%." The stage label communicates what is happening. The percentage communicates how much is left. Both together are more informative than either alone.
We emit progress events every 3 seconds during active processing. More frequent updates would overwhelm the WebSocket connection on slower networks. Less frequent updates would make the progress bar feel choppy.
When WebSocket is not enough
We shipped WebSocket-only progress and immediately heard from users who saw no updates at all. Corporate firewalls blocked the connection upgrade. Proxy servers stripped WebSocket headers. Mobile networks dropped long-lived connections.
The fix was a polling fallback. When the WebSocket connection fails after a few reconnection attempts with exponential backoff, the client switches to API polling. Every 10 seconds, it queries the transcription status endpoint and gets the same progress data that WebSocket would have delivered.
The fallback is transparent to the user. They see the same progress bar, the same stage labels, the same completion notification. The only difference is slightly less granular updates. In production, roughly 5-10% of users rely on this fallback. Without it, those users would have no progress indication at all.
This dual-transport approach made the system network-agnostic. We stopped receiving "it seems frozen" support messages from users behind corporate networks.
Making progress follow the user, not the session
Early on, progress was tied to the browser tab that initiated the upload. Close the tab, lose the progress. Start a transcription on your laptop, walk to a meeting, open the mobile app, and there is no indication that anything is processing.
Because we tracked WebSocket connections per user rather than per session, the fix was straightforward. The mobile app's WebSocket connection receives the same progress events as the laptop's connection. When the job completes, both devices get the completion event.
This extended to a subtle edge case on mobile. Authentication tokens expire while the app is backgrounded. A user starts a transcription, locks their phone, and returns 20 minutes later. The WebSocket reconnects, but the token has expired. We handle this by treating token expiry during long-running jobs as expected behavior (logged at debug level, not as errors) and refreshing the token before the reconnection handshake. The subscription to the in-progress job restores seamlessly with the new token.
Tracking connections per user instead of per session was a small architectural shift with outsized impact. Multi-device sync, background tab awareness, and mobile reconnection all fell out of the same design decision.
Letting users keep working
On the web, users can minimize the upload modal while processing continues. A "Continue in background" link appears after the audio has been uploaded and processing begins.
The user continues working: browsing other conversations, generating lenses, chatting with the AI. When processing completes, a toast notification appears with a "View" button that navigates to the finished conversation.
This works because the background processing registry listens for WebSocket completion events at the app level, regardless of which page the user is on. The queue-based architecture made this possible without additional server-side work.
Handling the jobs that slip through
We discovered the hard way that retry logic does not cover every failure mode. A server deployment during active processing left transcriptions permanently stuck in "processing" status. Users saw a job that appeared to be running but would never complete. They contacted support.
A cron job now runs hourly and scans for zombie transcriptions: jobs stuck in "pending" or "processing" status for more than 24 hours. These are marked as failed with a descriptive error message. Any orphaned temporary files are deleted from cloud storage.
Before this, a single unlucky restart could leave corrupted state in the database indefinitely. Now, the system self-heals. The worst case is that a user waits until the next hourly sweep before the UI acknowledges the failure and lets them retry.
What this changed about our architecture
Building real-time progress was not a single feature. It was a series of architectural decisions that compounded.
Every long-running operation should be queue-based. We started with transcription, but the pattern has since expanded to other processing pipelines. The separation between "accept the request" and "do the work" is now a default assumption in our architecture, not an exception.
Real-time features need a fallback transport. WebSocket is the happy path. Polling is the safety net. Designing for both from the start is cheaper than retrofitting after users report failures. This principle now applies to any feature that pushes updates to clients.
Self-healing beats perfect error handling. No amount of retry logic will cover a server restart mid-job, a corrupted file that passes validation, or an unrecoverable upstream API error. Accepting that some jobs will fail and building automated cleanup is more robust than trying to prevent every failure.
User-level tracking, not session-level. This single decision, mapping connections to user IDs instead of session tokens, eliminated an entire class of problems. Multi-device sync, background processing awareness, and mobile reconnection all work because of how we chose to index WebSocket connections.
Real-time progress for long-running tasks is a system problem, not a UI problem. It requires coordination between the job queue, the WebSocket layer, the polling fallback, and the cleanup cron. Each component handles its own failure modes. Together, they provide a reliable experience for operations that take anywhere from 15 seconds to 10 minutes.


